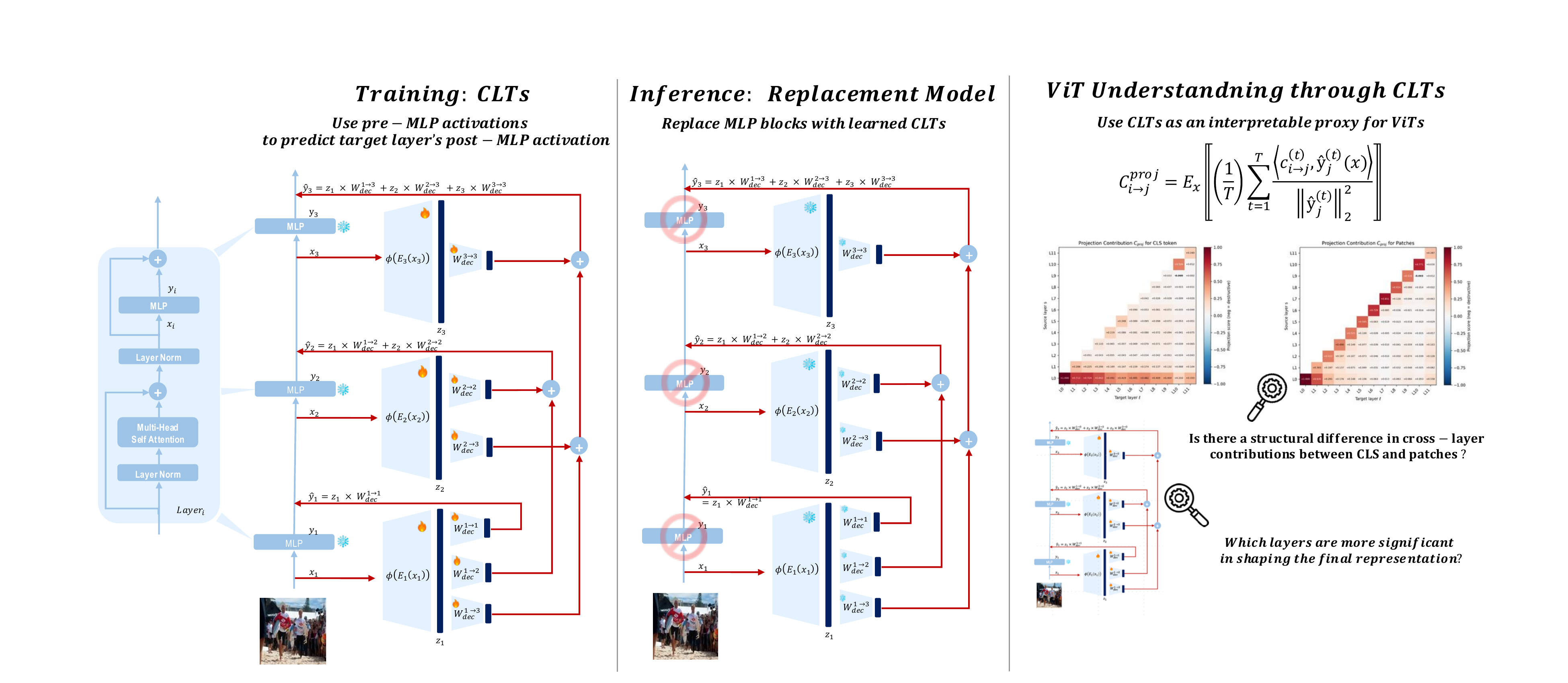
Figure 1. Overview of the Cross-Layer Transcoder (CLT) framework. Left: each CLT encodes LN2 activations into sparse codes zℓ and reconstructs MLP outputs yℓ via triangular decoders. Middle: at inference, CLTs replace MLPs across layers, preserving zero-shot performance. Right: CLTs serve as an interpretable proxy for ViTs to understand the cross-layer contributions of different token types and identify the most significant layers in shaping the ViT's final representations.